[ JS, PHP, Scraping ]
Web scraping is a technique used for extracting large amounts of data from websites, which can then be used for various purposes such as market research, data analysis, or data-driven decision-making. In this article, we will walk through the front-end code for a PHP web scraper that was built to scrape data from autotrader.co.uk, a European car dealer website.
Before diving into the code, it is important to note that this code is presented only for a presentation, and it is not meant to be used ‘as is’. Additionally, the scraper supports proxy servers and is basically bulletproof because of the techniques used in code to detect any failures and fix them during the execution. Also, it supports multiple instances, and the UI has controls to start scraping at different locations which comes handy quite often.
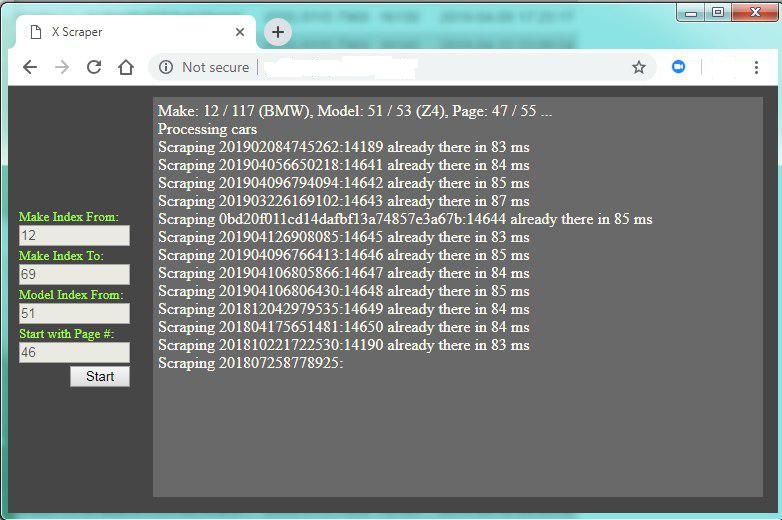
The front-end code consists of an HTML file, ‘index.html,’ and a JavaScript file, ‘app.js.’ The HTML file contains the basic structure of the user interface, which includes input fields for the make index, model index, and page index. These input fields allow the user to specify the range of data they want to scrape. Additionally, the HTML file contains a ‘Start’ button, which triggers the scraping process. The JavaScript file, on the other hand, contains the code that actually scrapes the data.
To begin, the JavaScript file starts by setting some constants for delay times between scraping requests. These constants, DELAY_CARS, DELAY_IDS, and DELAY_TRY_AGAIN, are used to ensure that the scraping process runs smoothly without overloading the website’s servers.
Next, the script defines a sleep function that is used to pause the execution of the script for a specified amount of time. This function is useful for ensuring that the scraper does not send too many requests to the website at once, which could lead to server overload or IP blocking. The rnd function generates a random number between two specified values, which is used to randomize the delay times between scraping requests. This randomization helps to further ensure that the website’s servers are not overloaded and that the scraper is not detected and blocked. The request function is used to send HTTP requests to the website’s servers. This function takes a payload object as an argument, which contains the URL to be scraped and any other necessary parameters. The function returns a Promise object, which resolves to the server’s response.
Here’s the main backend code in PHP:
function scrapeCarInfo($id, $proxy)
{
$GLOBALS['db']->where("carId", $id);
$res = $GLOBALS['db']->getOne("autoradar_cars");
if ($res !== null) {
return (json_encode(["id" => $id, "index" => $res['id'], "notes" => 'already there']));
}
if (strlen($id) > 20) {
// new car
$response = json_decode(request(array('url' => 'https://www.autotrader.co.uk/json/new-cars/derivative/get?id=f0d8e2aea02747a998f94f28c981a0eb', 'proxy' => $proxy)));
if (property_exists($response, 'ERR_CODE')) return json_encode($response);
$ci = ($response);
usleep(250000);
$response = json_decode(request(array('url' => 'https://www.autotrader.co.uk/json/dealers/search/by-derivative?derivativeId=f0d8e2aea02747a998f94f28c981a0eb&postcode=e161xl', 'proxy' => $proxy)));
if (!is_array($response)) return $response;
$di = ($response);
$title = $ci->make . " " . $ci->name;
$phone = $di[0]->review->dealer->phoneNo1;
$price = $ci->price;
$href = 'https://www.autotrader.co.uk' . $ci->uri;
} else {
// used car
$response = json_decode(request(array('url' => ('https://www.autotrader.co.uk/json/fpa/initial/' . $id), 'proxy' => $proxy)));
if (property_exists($response, 'ERR_CODE')) return json_encode($response);
$carInfo = ($response);
$title = $carInfo->advert->title;
$phone = $carInfo->seller->primaryContactNumber;
$price = $carInfo->advert->price;
$href = 'https://www.autotrader.co.uk/classified/advert/' . $id;
}
// Save data
$data = array(
'carId' => $id,
'title' => $title,
'href' => $href,
'phone' => $phone,
'price' => $price
);
$insertedId = $GLOBALS['db']->insert('autoradar_cars', $data);
$response = array("id" => $id, "index" => $insertedId);
return json_encode($response);
}The updateUI function is used to update the user interface with information about the scraping progress. This function extracts information from the scraping process, such as the make index, model index, and page index, and displays it in the appropriate input fields. Finally, the script defines an array of proxy servers that are used to send the scraping requests. This array contains a list of IP addresses and port numbers, which are used to randomize the proxy server used for each request.
In conclusion, the PHP web scraper presented here is a simple yet effective tool for scraping data from autotrader.co.uk. While the code presented here is not meant to be used ‘as is’, it provides a solid foundation for building more complex scraping tools. With the right modifications and adjustments, this scraper can be used to extract a wide range of data from other websites as well.
Leave a reply