[ .NET, C#, SQLite, iTextSharp ]
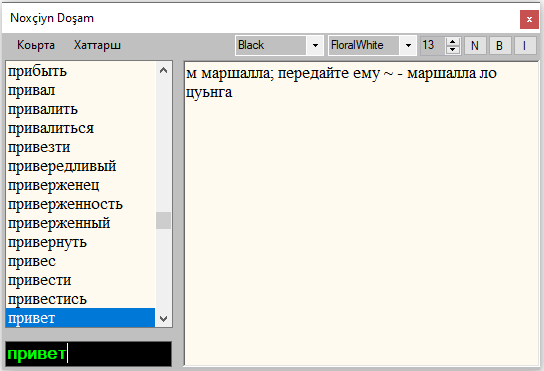
A few years ago I worked as a researcher in linguistics, analyzing and studying text documents was a crucial part of the job. However, the manual process of counting and studying the frequency of words in electronic documents can be a tedious and time-consuming task. To solve this problem, and with the suggestion of my supervisor, I developed this app to streamline the process. It is designed to support batch processing of various types of electronic text documents, including pdf, txt, doc, docx, odt, xlsx, htm, html, and rtf formats. It also supports a single data warehouse, making it easy to store, search and retrieve information.
One of the essential functions of the app is counting the number of characters and words in each document. This feature saves users time and energy, as it automatically generates these statistics and presents them in an easy-to-read format. Another critical function of the app is the study of the frequency and density of words in each document. This feature allows users to gain insights into the use of specific words and phrases in each document and the overall language patterns used by the author. The app also allows users to search for words according to given conditions, making it easier to study specific topics or themes in a document.
The app was developed using C#, a programming language that is widely used in the development of Windows applications. It also uses the ITextSharp library, which is an open-source library used for generating and manipulating PDF documents. To store the data generated by the app, I decided to use an SQLite database. SQLite is a lightweight, open-source database that is widely used in mobile and desktop applications. It is a self-contained, serverless database that requires minimal setup and administration, making it an ideal choice for small to medium-sized applications.
Overall, the app I developed is an excellent tool for researchers, students, and anyone who works with electronic text documents. It streamlines the process of studying, ranking and analyzing the frequency of words, saving users time and energy. It is written using modern programming languages and adheres to best coding practices, ensuring it is easy to maintain and extend.
Download from GitHub: DoshStat